
前回の記事で、scikit-learnの手書き数字の学習の内容を紹介しましt。
今日の記事は、PyTorch+MNISTの手書き数字データセットを使って学習とその後の分類(推論)を紹介します。
目次
PyTorchとは
![]()

PyTorch(http://pytorch.org/)はFacebookの人工知能研究グループにより開発されたPython向けのオープンソース機械学習のライブラリです。
PyTorchは元々「Torch(トーチ)」「Lua言語」書かれていましたが、PyTorchはそれのPython版です。2018年10月前半にリリースされ、今安定しているのはPyTorch 0.4.1です。
PyTorchは2016年後半に発表された比較的新しいライブラリです。他の機械学習のフレームワークと比べると、後発ではありますが、最近人気が増え続けています。注目すべき機械学習フレームワークの一つだと言えるでしょう。
MNISTとは
MNIST(http://yann.lecun.com/exdb/mnist/)とは、「Mixed National Institute of Standards and Technology database」の略で、手書きの数字「0~9」とその正解ラベルがセットになっているデータセットです。手書き数字の画像データセットが70,000個あります。
データセットにある手書き文字は28ピクセル×28ピクセルの画像になっており、784次元のデータとなります。この784次元のデータを使って0~9を分類します。
scikit-learnのレ記事でも手書き数字の認識を機械学習のアプローチで体験してみましたが、今回は、ニューラルネットワークの手法を用いて、学習させていきます。
また、scikit-learnの手書き数字の一つの画像は8×8の画像で、全部で64ピクセルということに対して、MINISTのデータは、28×28の画像で、全部で784ピクセルがあるということで、MNISTデータの「粒度」はscikit-learnのデータと比べ、より細かく、ディテールが多いです。
MINISTの手書き数字データセットは様々な機械学習フレームワークから簡単に利用することができます。
例えば、Keras、PyTorch、Chainerも一行でデータセットのロードすることができます。
今回の記事の内容はGoogle Colabで実行できます。
PyTorchのインストール
下記のようにGoogle Colabが提供している標準な方法を使ってインストールします。
from os.path import exists
from wheel.pep425tags import get_abbr_impl, get_impl_ver, get_abi_tag
platform = '{}{}-{}'.format(get_abbr_impl(), get_impl_ver(), get_abi_tag())
cuda_output = !ldconfig -p|grep cudart.so|sed -e 's/.*\.\([0-9]*\)\.\([0-9]*\)$/cu\1\2/'
accelerator = cuda_output[0] if exists('/dev/nvidia0') else 'cpu'
!pip install -q http://download.pytorch.org/whl/{accelerator}/torch-0.4.1-{platform}-linux_x86_64.whl torchvision
import torch
print(torch.__version__)
実行結果:0.4.1
必要なパケージを導入する
まず、torchvisionが必要です。torchvisionとは,PyTorchのコンピュータービジョン用のパッケージで,データセットのロードや画像の前処理の関数などが入っています。
今回使うMNISTのデータセット以外に、16種類のデータセットが予め入っています。こちらのデータを使って、練習するのもいいですね。
今回は、torchvision.datasetsを使って、MNISTのデータを導入します。
import matplotlib.pyplot as plt import torchvision.transforms as transforms from torch.utils.data import DataLoader from torchvision.datasets import MNIST
データセットのダウンロード
mnist_data = MNIST('~/tmp/mnist', train=True, download=True, transform=transforms.ToTensor())
data_loader = DataLoader(mnist_data,batch_size=4,shuffle=False)
データの中身を見てみる
data_iterator = iter(data_loader) images, labels = data_iterator.next()
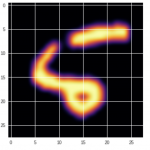
1つ目のデータを可視化してみる
data = images[2].numpy()
plt.imshow(data.reshape(28, 28), cmap='inferno', interpolation='bicubic')
plt.show()
print('ラベル:', labels[0])
実行結果:
ラベル: tensor(5)

学習データと検証データを用意する
学習のデータか検証のデータかは、trainという引数で決めています。
train=Trueの場合は、学習データとしてロードします。 train=Falseの場合は、検証データとしてロードします。
PyTorchでは、こんなやり方が分かりやすいですね!
# 学習データ
train_data_with_label = MNIST('~/tmp/mnist', train=True, download=True, transform=transforms.ToTensor())
train_data_loader = DataLoader(train_data_with_label,batch_size=4,shuffle=True)
# 検証データ
test_data_with_label = MNIST('~/tmp/mnist', train=False, download=True, transform=transforms.ToTensor())
test_data_loader = DataLoader(test_data_with_label,batch_size=4,shuffle=False)
ニューラルネットワークを定義
ニューラルネットワーク(MLP)は torch.nn パッケージを使用して構築できます。
親クラスはPyTorchでは、nn.Moduleとなります。
そして、マルチレイヤーパーセプトロン (ニューラルネットワーク)の定義をしていきます。
ネットワークをFeed Forwardネットワークにします。
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
class MLP(nn.Module):
def __init__(self):
super().__init__()
#入力層から中間層(隠れ層)
self.l1 = nn.Linear(28 * 28, 50)
# 中間層(隠れ層)から出力層
self.l2 = nn.Linear(50, 10)
def forward(self, x):
x = x.view(-1, 28 * 28)
x = self.l1(x)
x = self.l2(x)
return x
モデル
model = MLP()
コスト関数と最適化手法を定義
PyTorchでは代表的なコスト関数や最適化手法はあらかじめ提供されています。
コスト関数にクロスエントロピー、最適化手法にSGDをします。
optimizer.SGDに引数として最適化対象のパラメータ一覧を渡しています。
PyTorchでは
optimizer = optimizer.SGD(model.parameters(), lr=0.01)
という形で、モデルに最適手法を適用していますね。
import torch.optim as optimizer # ソフトマックスロスエントロピー criterion = nn.CrossEntropyLoss() # SGD optimizer = optimizer.SGD(model.parameters(), lr=0.01)
学習
早速学習させてみましょう!まず、学習回数を4回にしてみましょう
学習ループ内では次のような作業を順次実行していきます:
# 最大学習回数
MAX_EPOCH=4
for epoch in range(MAX_EPOCH):
running_loss = 0.0
for i, data in enumerate(train_data_loader):
# dataから学習対象データと教師ラベルデータを取り出します
train_data, teacher_labels = data
# 入力をtorch.autograd.Variableに変換
train_data teacher_labels = Variable(train_data), Variable(teacher_labels)
# 計算された勾配情報を削除します
optimizer.zero_grad()
# モデルでの予測を計算します
outputs = model(train_data)
# lossとwによる微分計算します
loss = criterion(outputs, teacher_labels)
loss.backward()
# 勾配を更新します
optimizer.step()
# 損失を累計します
running_loss += loss.data[0]
# 2000ミニバッチずつ、進捗を表示します
if i % 2000 == 1999:
print('学習進捗:[%d, %d] 学習損失(loss): %.3f' % (epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('学習終了')
実行結果
/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:27: UserWarning: invalid index of a 0-dim tensor. This will be an error in PyTorch 0.5. Use tensor.item() to convert a 0-dim tensor to a Python number 学習進捗:[1, 2000] 学習損失(loss): 0.810 学習進捗:[1, 4000] 学習損失(loss): 0.397 学習進捗:[1, 6000] 学習損失(loss): 0.362 学習進捗:[1, 8000] 学習損失(loss): 0.349 学習進捗:[1, 10000] 学習損失(loss): 0.329 学習進捗:[1, 12000] 学習損失(loss): 0.317 学習進捗:[1, 14000] 学習損失(loss): 0.310 学習進捗:[2, 2000] 学習損失(loss): 0.321 学習進捗:[2, 4000] 学習損失(loss): 0.298 学習進捗:[2, 6000] 学習損失(loss): 0.297 学習進捗:[2, 8000] 学習損失(loss): 0.301 学習進捗:[2, 10000] 学習損失(loss): 0.311 学習進捗:[2, 12000] 学習損失(loss): 0.296 学習進捗:[2, 14000] 学習損失(loss): 0.302 学習進捗:[3, 2000] 学習損失(loss): 0.284 学習進捗:[3, 4000] 学習損失(loss): 0.297 学習進捗:[3, 6000] 学習損失(loss): 0.296 学習進捗:[3, 8000] 学習損失(loss): 0.294 学習進捗:[3, 10000] 学習損失(loss): 0.280 学習進捗:[3, 12000] 学習損失(loss): 0.301 学習進捗:[3, 14000] 学習損失(loss): 0.299 学習進捗:[4, 2000] 学習損失(loss): 0.274 学習進捗:[4, 4000] 学習損失(loss): 0.290 学習進捗:[4, 6000] 学習損失(loss): 0.288 学習進捗:[4, 8000] 学習損失(loss): 0.284 学習進捗:[4, 10000] 学習損失(loss): 0.287 学習進捗:[4, 12000] 学習損失(loss): 0.284 学習進捗:[4, 14000] 学習損失(loss): 0.303 学習終了
検証データを使った検証
import torch
count_when_correct = 0
total = 0
#
for data in test_data_loader:
#
test_data, teacher_labels = data
#
results = model(Variable(test_data))
#
_, predicted = torch.max(results.data, 1)
#
total += teacher_labels.size(0)
count_when_correct += (predicted == teacher_labels).sum()
print('正解率:%d / %d = %f'% (count_when_correct, total, int(count_when_correct)/int(total)))
実行結果:
正解率:9204 / 10000 = 0.920400
検証データを決める
test_iterator = iter(test_data_loader)
# ここで回数を増減して、違うテストデータを取り出せます
test_data, labels = test_iterator.next()
test_data, labels = test_iterator.next()
test_data, labels = test_iterator.next()
#
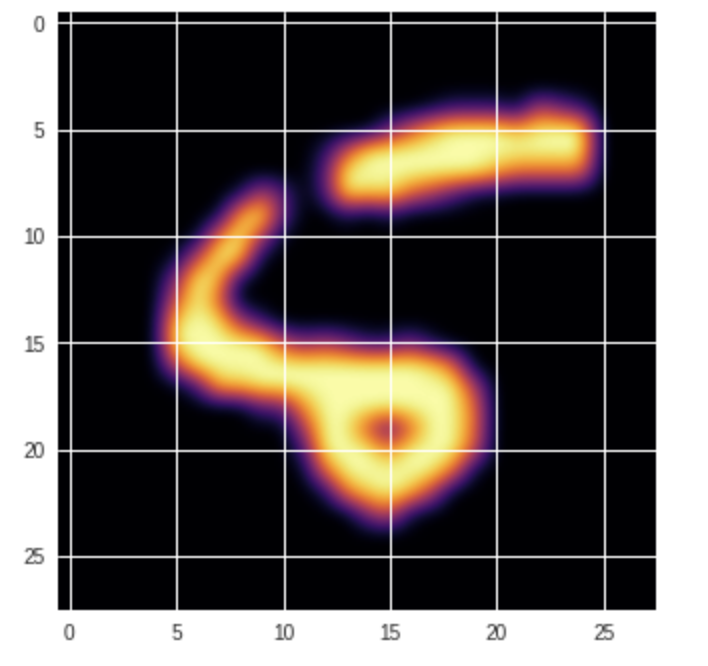
results = model(Variable(test_data))
_, predicted_label = torch.max(results.data, 1)
plt.imshow(test_data [0].numpy().reshape(28, 28), cmap='inferno', interpolation='bicubic')
print('ラベル:', predicted_label[0])
実行結果:
ラベル: tensor(6)

まとめ
いかがですか?この記事の内容でPyTorchの使い方のイメージを摘むことができましたでしょうか?
ニューラルネットワークの定義の仕方がとても分かりやすいかと思います。
では、また別の機会でPyTorchの使い方を紹介していきたいと思います。
[amazonjs asin=”4798055476″ locale=”JP” title=”PyTorchニューラルネットワーク実装ハンドブック (Pythonライブラリ定番セレクション)”]
[amazonjs asin=”479815718X” locale=”JP” title=”現場で使える!PyTorch開発入門 深層学習モデルの作成とアプリケーションへの実装 (AI & TECHNOLOGY)”]