
人工知能はアツイ!
機械学習(machine learning)と深層学習の機運が高まっています!
海外に限らずに、日本も機械学習と深層学習の研究が盛んになっており、産業界では、深層学習などの導入がすでに始まっています。
日本の深層学習フレームワークと言えば、Preferred Networks社(https://www.preferred-networks.jp/ja/)のChainerがあります:https://chainer.org/
フレームワークに留まらず、深層学習に特化したディープラーニングプロセッサーも開発中です。
これから、間違いなく、機械学習と深層学習はますます盛り上がって大発展する分野で、この分野の人材のニーズも増えるでしょう。
機械学習、深層学習を始めようと考えているあなた、このサイトにたどり着いて、よかったです!
2019年は、もう機械学習、深層学習を始める最高のタイミングです!笑
scikit-learnって本当にやってみる価値がありますね!
おすすめです! #機械学習You should start with scikit-learn if you want to dive into #MachineLearning worth to give it a try!
— 川島@ソフトウェア、Web、アプリ、IoT作るのが大好き (@kokensha_tech) 2018年12月24日
人工知能の分野においては、細分化すると、下の図のように、機械学習、ニューラルネットワーク、深層学習がありますが、いきなり、最近のホットな深層学習トピックは、ハードルが高いので、まず、は機械学習の基礎を抑えた方が堅実でしょう。
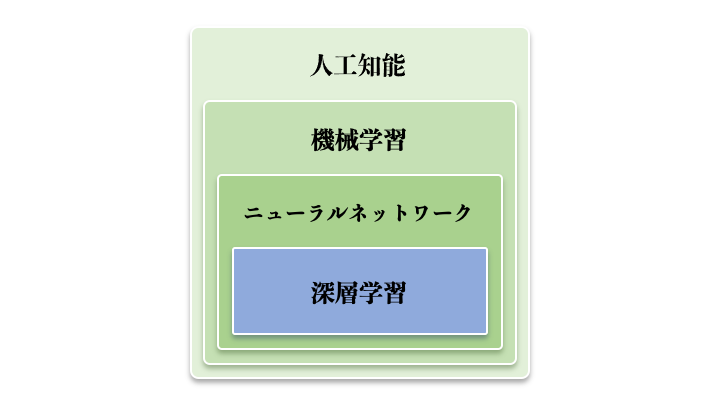

機械学習の全体に関する解説は、下記の記事を参考してください。
今日のこの記事は、まず機械学習のフレームワークの定番を紹介します!
目次
機械学習の定番フレームワークscikit-learnの紹介
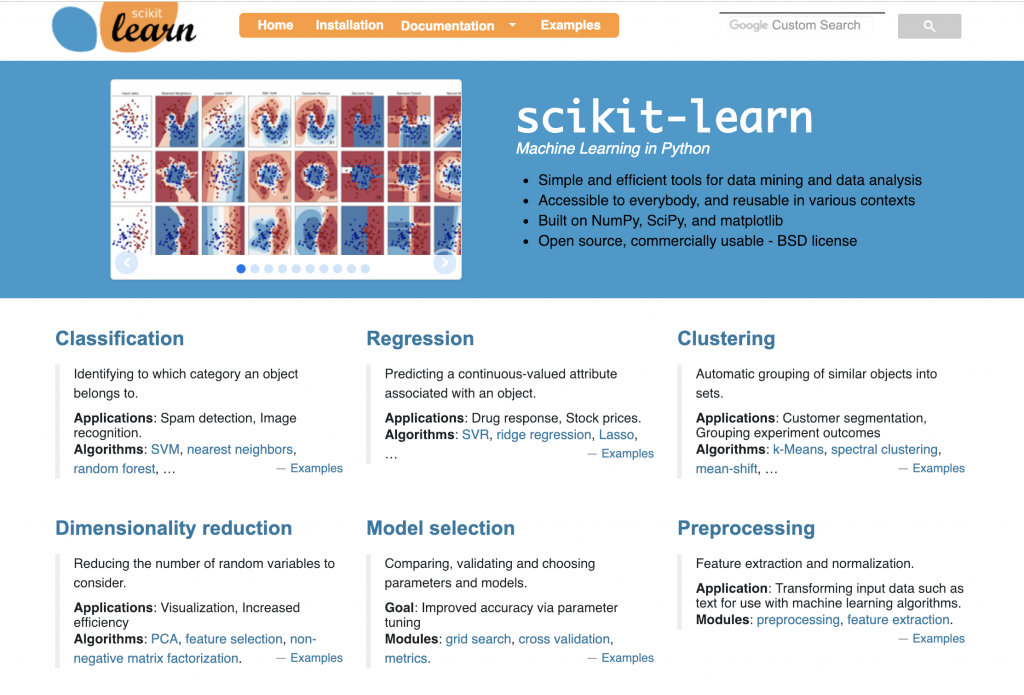

scikit-learnとは
scikit-learn(サイキットラーン)は Python向けの機械学習フレームワークです。
機械学習のアルゴリズムを幅広く実装されています。
特に機械学習の学習者にとってはscikit-learnはとても良い教材になっています。
あらかじめ提供されるデータセットもたくさんありまして、データセットの整備の労力もかけることなく、すぐ機械学習の勉強を始められます。
scikit-learnのサイトにチュートリアルのコンテンツも豊富になっています。初心者にとっては、こんな嬉しいことがあっていいのかぐらい、貴重なものです!
何ができますか?
分類
- SVM(サポートベクトルマシン、線形サポートベクトルマシン)
- K近傍法
- ランダムフォレスト
回帰
- 回帰
- ラッソ回帰
- リッジ回帰
- SVR
クラスタリング
- クラスタ分析(Clustering)
- K平均法(KMeans)
- 混合ガウス分布(GMM)
- 平均変位法(MeanShift)
次元削減
- 主成分分析(PCA)
- 非負値行列因子分解(NMF)
ライセンス
- BSDライセンス、商用利用可(https://github.com/scikit-learn/scikit-learn/blob/master/COPYING)
ホームページのURL
github url
scikit-learnの特徴
- 機械学習で使われる上記のような様々なアルゴリズムに対応しています。
- すぐに機械学習を試すことができるようにサンプルデータのデータセットが含まれています。これから紹介する内容もデータセットが含まれていますので、データの用意は躊躇、苦労せずにすぐにデータを導入して始められます。
- 機械学習お結果を検証する機能を持っています。
- 機械学習でよく使われる他のPython数値計算ライブラリ(Pandas、NumPy、Scipy、Matplotlibなど)と連携しやすいように設計されています。
- BSDライセンスのオープンソースのため無料で商用利用が可能
- 大量、豊富なサンプル:https://scikit-learn.org/stable/auto_examples/index.html
- 一貫された分かりやすいAPI
例えば モデルインスタンス生成 学習させる:fit() (学習済モデルを使って) 予測する:predict()
scikit-learnの datasetsに何があるかを確認しましょう
他にもいくつかデータセットが用意されていて、実験と勉強に使うにはとても便利です。
例えば下記の七種類の練習用のデータセット(Toy datasets)があります:
①ボストンの住宅不動産の値段のデータセット(回帰の学習用)
datasets.load_boston()
米国ボストン市郊外における地域別の住宅価格のデータセットです。
②乳がんのデータセット(分類の学習用)
datasets.load_breast_cancer()
③アヤメの計測データセット(分類の学習用)
datasets.load_iris()
“setosa”, “versicolor”, “virginica” という 3 種類の品種のアヤメのがく片 (Sepal)、花弁 (Petal) の幅および長さを計測したデータです。
④ワインのデータセット(分類の学習用)
datasets.load_wine()
⑤手書き数字のデータセット(分類の学習用)
datasets.load_digits()
0 ~ 9 の 10 文字の手書きの数字を 64 (8×8) 個の画素に分解したものです。
⑥糖尿病患者の診断データ(回帰の学習用)
datasets.load_diabetes()
糖尿病患者 442 人の検査数値と 1 年後の疾患進行状況データです。
⑦生理学的特徴と運動能力の関係(多変量回帰)
datasets.load_linnerud()
20 人の成人男性に対してフィットネスクラブで測定した 3 つの生理学的特徴と 3 つの運動能力の関係。
これ以外も、九種類の大規模データセット(Real world datasets)、自動生成データセット(Generated datasets)が提供されています。
また、外部からデータセットの読み込みも可能です。
様々な種類のデータセットが用意されていて、機械学習の勉強はとても始めやすくなっていますね。
scikit-learnのインストール
ここからのコマンドやコードの実行はjupyter notebookやGoogle Colabで行うことをお勧めします。コピペで実行できます。
pip install -U scikit-learn
PCの環境でPythonを入れて Jupyter Notebookを起動したい場合は、下記の記事を参考してください。
scikit-learnバージョンの確認
import sklearn print(sklearn.__version__)
2018年12月25日現在の最新版は:0.20.1 です。
これで、すぐscikit-learnを使えます、上の7種類のデータセットも簡単にロードして、色々いじって勉強できますよ!こんなに便利なフレームワークがないでしょう!笑
まず、その中のワインデータを一つの例として見ていきましょう!
ワインのデータ
まず、必要なライブラリをインポートします。
それから、ワインデータもロードして、そのまま表示してみましょう。
#グラフ描画するためのライブラリ、 import matplotlib.pyplot as plt # from mpl_toolkits.mplot3d import Axes3D # from sklearn import datasets # ワインのデータを取り込みます wine = datasets.load_wine() print(wine)
これを実行しますと下記のような結果が出力されます。
{'data': array([[1.423e+01, 1.710e+00, 2.430e+00, ..., 1.040e+00, 3.920e+00,
1.065e+03],
[1.320e+01, 1.780e+00, 2.140e+00, ..., 1.050e+00, 3.400e+00,
1.050e+03],
[1.316e+01, 2.360e+00, 2.670e+00, ..., 1.030e+00, 3.170e+00,
1.185e+03],
...,
[1.327e+01, 4.280e+00, 2.260e+00, ..., 5.900e-01, 1.560e+00,
8.350e+02],
[1.317e+01, 2.590e+00, 2.370e+00, ..., 6.000e-01, 1.620e+00,
8.400e+02],
[1.413e+01, 4.100e+00, 2.740e+00, ..., 6.100e-01, 1.600e+00,
5.600e+02]]), 'target': array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2]), ...省略...
ウィンデータを表形式で表示する
pandasを使えば、表形式で、データを見ることができます。
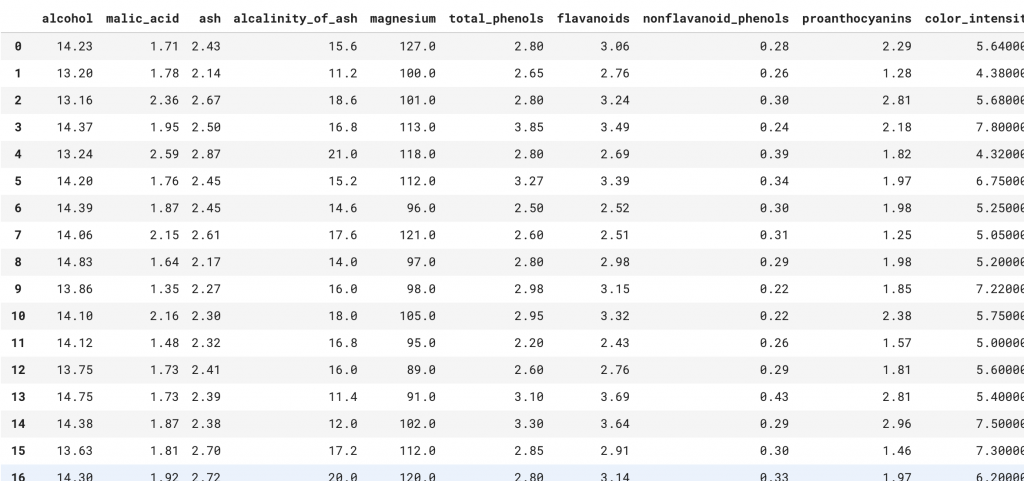

最初の二列(特徴量)を表示したい場合は
# 最初の二つの特徴量を使います。 first_two_features = wine.data[:, :2] # 全てのデータを表示します。 print(wine.data) # 最初の二列のデータを表示します(今回使うデータ) print(first_two_features)
これで、最初の二列だけが出力されます。
ワインデータのラベル(教師データ)
teacher_labels = wine.target print(teacher_labels)
下記のデータが表示されます。
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
これは、三種類のワインの種類ですね。分類するときのClassになりますね。
最初の2列ではなく、PCAで次元削減後のデータを使う場合
ところで、PCAは何?
教師なし機械学習のPCA
PCAは主成分分析です。PCAは「sklearn.decomposition」というモジュールで実装されています。行列の分解などのアルゴリズムが含まれています。
PCAとは、相関のある多数の変数から相関のない少ない変数で全体のばらつきを最もよく表す「主成分」とを算出するアルゴリズムです。
データセットに含まれる次元が多いと、データ分析をするにせよ機械学習をするにせよ分かりにくさが増えます。 そういうとき、主成分分析を使えば取り扱う必要のある次元を圧縮 (削減) でできます。
もちろん、ここでいう圧縮というのは「非可逆」なもので、いくらか情報が圧縮することで失われます。
なぜ次元削減するのか
データに次元がいっぱいあればあるほどいいわけではありません。
機械学習の対象データが特徴量が少ないと効果的な学習ができず、正しい結果になりにくいですが
逆に数百、数千の特徴量(feature)がある場合、学習プロセスが逆に極端に遅くなりますし、いい解を見つけにくくなることがほとんどです。
この問題は、よく次元の呪い(curse of dimensionality)と呼ばれます。

データセットの中に、もっともデータの本質を表す特徴量だけに絞って、学習させるのが一番効果的です。
ここでPCAを使ってウィンデータの次元削減を実施して、体験します。
まず、PCAを導入します。
# scikit-learnの(PCA)主成分分析を使います。 from sklearn.decomposition import PCA
all_features = wine.data[:, :2]
feature_reduced = PCA(n_components=2).fit_transform(wine.data)
x_min, x_max = all_features[:, 0].min(), all_features[:, 0].max()
y_min, y_max = all_features[:, 1].min(), all_features[:, 1].max()
plt.figure(2, figsize=(12, 9))
plt.clf()
# 散布図グラフの描画
plt.scatter(all_features[:, 0], all_features[:, 1], s=300, c=teacher_labels,cmap=plt.cm.Set1,
edgecolor='k')
plt.grid(True)
次元削減PCAを使って、そもそもあった13個(列)の特徴量を二つに減らして、それぞれ、X,Yにして、2Dのグラフで表現したものになります。
でも、これをみて、やはり混ぜているところがあって、目視しても、はっきり「分類」することができませんね。
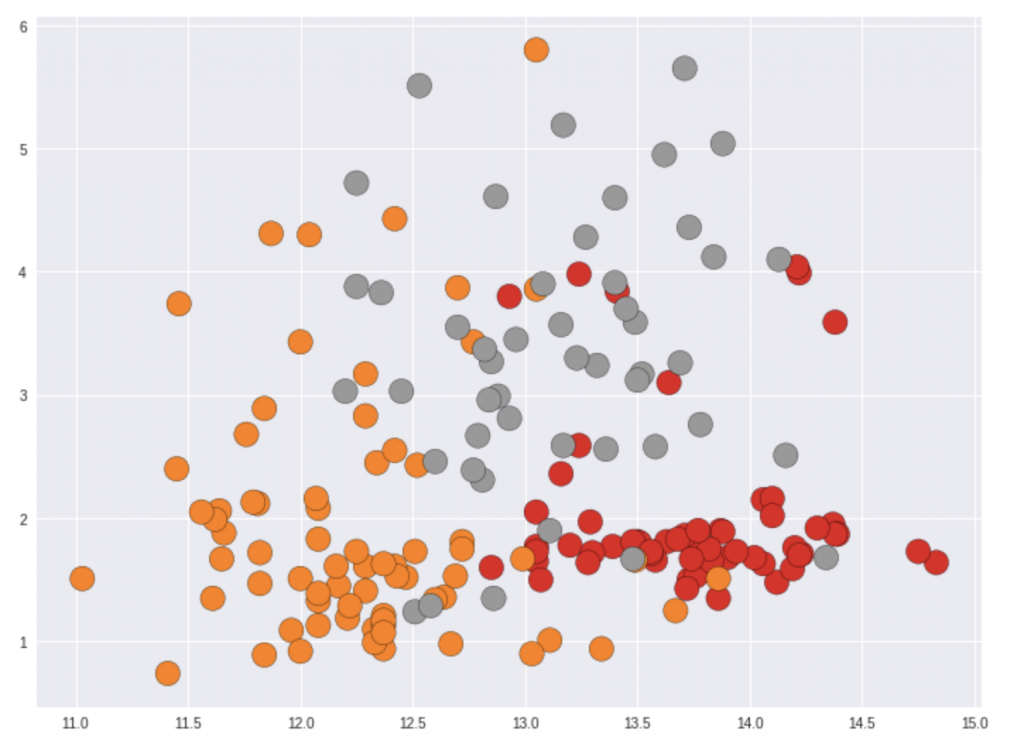

こういう時は、次元を増やしましょう!笑(なんのために減らしてんねん!)
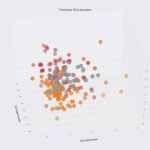
三次元でワインのデータを見てみましょう
# 同じデータですが、3次元で表現されたときの空間構造を観察しましょう。
# 最初の三つの主成分分析次元を描画します。
#
fig = plt.figure(1, figsize=(12, 9))
#
ax = Axes3D(fig, elev=-140, azim=10)
#
feature_reduced = PCA(n_components=3).fit_transform(wine.data)
#
ax.scatter(feature_reduced[:, 0], feature_reduced[:, 1], feature_reduced[:, 2],c=teacher_labels,
cmap=plt.cm.Set1, edgecolor='k', s=270)
ax.set_title("First three PCA directions")
ax.set_xlabel("1st")
ax.w_xaxis.set_ticklabels([])
#
ax.set_ylabel("2nd")
ax.w_yaxis.set_ticklabels([])
#
ax.set_zlabel("3rd")
ax.w_zaxis.set_ticklabels([])
plt.show()
三次元のグラフが描画されます。
feature_reduced = PCA(n_components=3).fit_transform(wine.data)
この一行だけで、次元削減ができるのは便利ですよね!
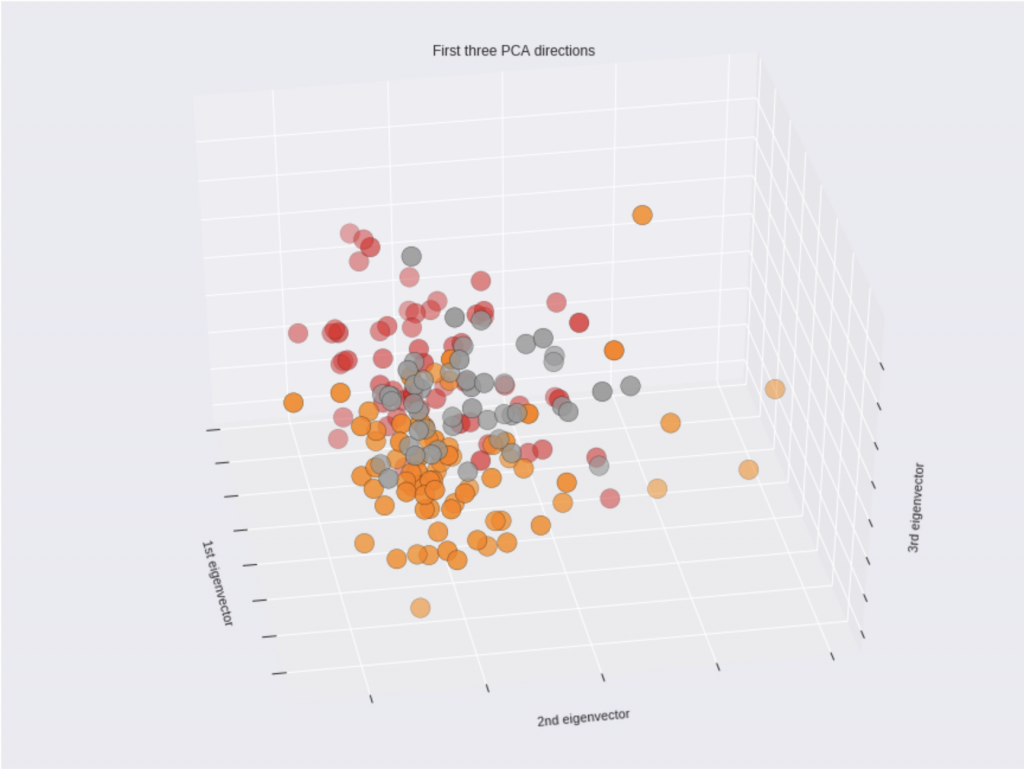

こうやって、データの中身を確認したり、二次元のデータをグラフにしてみたり、三次元のグラフにしてみたりすると、データセットへの理解が直感的になって、イメージがつきやすくなりますね。
ここでは、scikit-learnの使い方を伝えるために、ちょっと味見的に、PCAを使ってみましたが
実際に、データを分類する時は、様々なアプローチをとってみて、一番データの本質を反映する特徴量を特定する必要があります、一番データの本質を反映するデータを使うことで、機械学習が最大な効果を発揮することができます。
まとめ
この記事では、簡単ではありますが、最初のscikit-learnの紹介として、少し理解していただければ幸いです。
scikit-learnの充実した機能とpythonのシンプルさとパワフルさを加えて、本当に、すぐ機械学習の勉強を始められますね。
2019年ぜひチャレンジしていただきたいと思います。そして日本の人工知能産業の底力になってください。
次の記事は、scikit-learnのいろんなデータを使って、分類(classification)や回帰(regression)のアルゴリズムを一緒に勉強していきたいと考えています!
では、また!Happy Machine Learning!
[amazonjs asin=”4873117984″ locale=”JP” title=”Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎”]
[amazonjs asin=”4873118344″ locale=”JP” title=”scikit-learnとTensorFlowによる実践機械学習”]
