Azure のCognitive Service APIを利用して写真から文章作成
今日の記事はAzure のCogntive Service APIを利用して写真から(短い)文章作成する方法を紹介したいと思います。
機械学習において、データの学習の部分は、どうしても大量の演算計算パワーを有するコンピューターが必要ですが、学習済みのモデルがあれば、Raspberry Pi上で利用することができます。
あるいは、Movidius NCSのようなVPU搭載しているモジュールを利用すれば、Raspberry Piは現場でも検出エッジデバイスとして十分活用できます。
最近人工知能関連のクラウドのAPIも大分成熟して来ましたので、Raspberry Piなどのエッジデバイスにモデルも待たず、演算パワーの必要な検出、分類作業をクラウドに任せることができます。
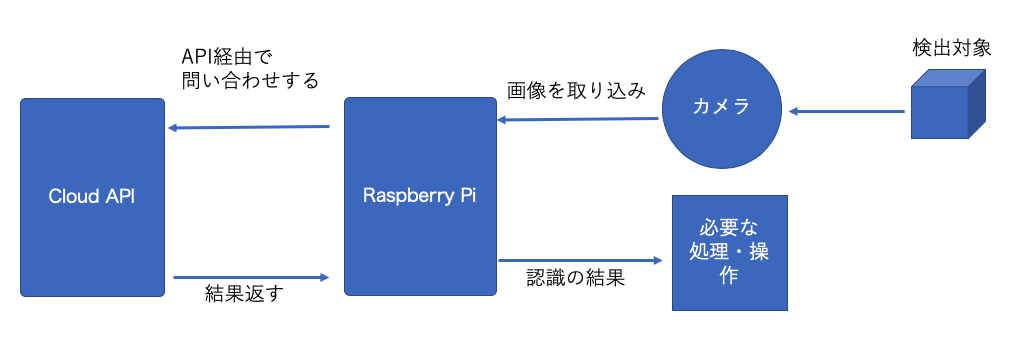
いわば頭脳をクラウドに置き、クラウドと連携しすることで、Raspberry Piが画像認識、分類などを実施するという形にすることで、さらに様々な可能性が見えてきます。
今回の記事は、それの例の一つとして、見ていきたいと思います。
目次
Microsoft Azure Cognitive Services
今回はMicrosoft Azure のAPIを利用します。
もちろん、類似しているサービスも他のサービスプロバイダー(Google Cloud PlatformやAmazon Web Serviceなど)に提供されていますので、興味のある方はぜひそれらも試してみてください。
Microsoft Azureのアカウントを取得しておいてください。無料のプランもありますので、すぐ始められます。
では、早速やってみましょう。
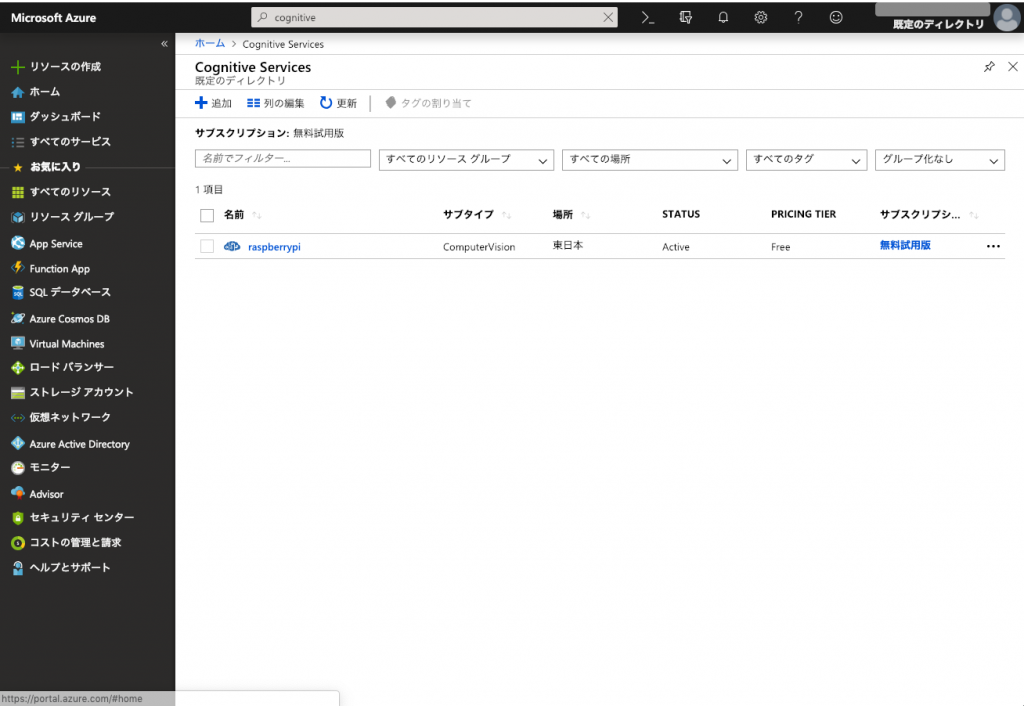
Microsoft Azureにログインしたら、ダッシュボードから、検索欄で「cognitive」で入力して、「Cognitive Services」を特定して、「追加」のボタンを押して、新しいプロジェクトを作ってください。
下記の写真のように、私がすでに「raspberrypi」というプロジェクトを作りました。もちろん、この名前は好きなように指定して良いです。
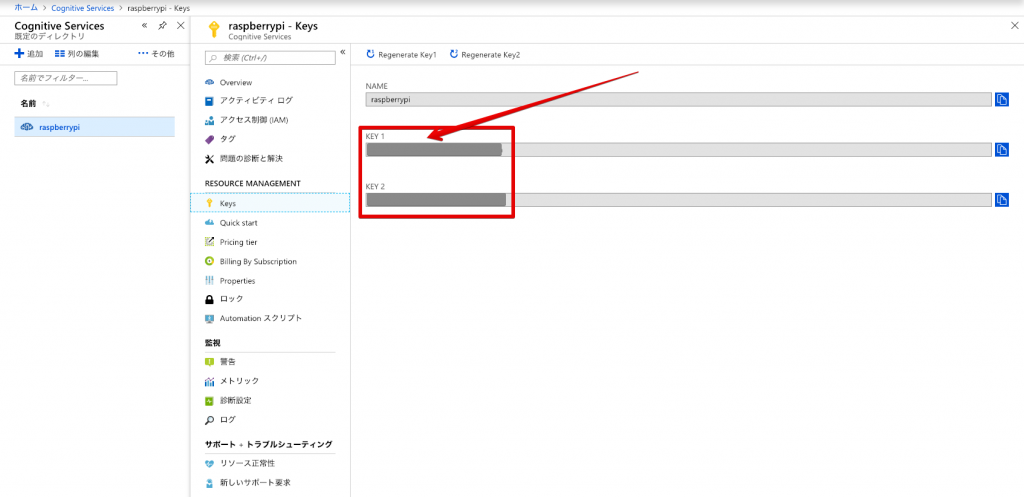
その後、「raspberrypi」のプロジェクトの「keys」というタブで、「subscription_key」を確認しておいてください。下のプログラムの中で指定する必要があります。
key1とkey2がありますが、どちらも使えます。
最後、「endpoint」のurlを確認しておきましょう。

私の場合は「https://japaneast.api.cognitive.microsoft.com/」となっております。
これの後ろに「vision/v2.0/」を追加して、今回のプログラムに使います。
注意:語尾の「/」が忘れがちですが、必須です。「/」がないと、エラーになって、正常に動作しません。
まず動作確認をGoogle Colabで簡単に実行します。
必要なパッケージを導入する
import requests import json from io import BytesIO
初期設定
「subscription_key」は、上のステップで確認したkey1かkey2を記入してください。
また、「vision_base_url」も無料プランか、有料プランかによって、変わります。使っているリージョンを確認したうえ、ここに設定してください。
私は日本のリージョンを使っていますので、「japaneast.api」で始まるurlとなります。
subscription_key = "xxxxxxxxxxxxxxxxxxxxxxxxxx" assert subscription_key vision_base_url = "https://japaneast.api.cognitive.microsoft.com/vision/v2.0/"
画像のキャプションを取得する関数
def getImageCaption(image_url):
analyze_url = vision_base_url + "analyze"
headers = {'Ocp-Apim-Subscription-Key': subscription_key }
params = {'visualFeatures': 'Categories,Description,Color'}
data = {'url': image_url}
response = requests.post(analyze_url, headers=headers, params=params, json=data)
response.raise_for_status()
analysis = response.json()
image_caption = analysis["description"]["captions"][0]["text"].capitalize()
return image_caption
写真指定
ネット上の任意の画像で良いです。ここではこの技術ブログの記事の中の写真を使います。
image_url = "https://kokensha.xyz/wp-content/uploads/2018/05/IMG_5338_small-768x576.png"
結果表示
print(getImageCaption(image_url))
結果は下記となります:
「A group of people on a city street」
画像を表示する
どんな画像なのかを表示してみましょう。
from PIL import Image
import matplotlib.pyplot as plt
image = Image.open(BytesIO(requests.get(image_url).content))
plt.imshow(image)
plt.axis("off")
plt.show()

これは私が秋葉原でRaspberry Pi Zeroを買いに行った時に撮った秋葉原の街頭の写真ですね。
「A group of people on a city street」という記述で、group of people:人たち、city:都市、都会、street:ストリート、街頭というポイントがちゃんと抑えていますね。
せっかくなので、もう一枚見てみましょう。
image_url = "https://kokensha.xyz/wp-content/uploads/2018/03/IMG_0903_small-768x512.jpg"
結果は下です:
「A close up of electronics」
「A close up of electronics」電子部品等のクローズアップ写真だというキャプションを得られましたね。実際の写真はこちらです。
実際の写真は下です:

これは、私がRaspberry Pi Zero WHを使って組み立てたインタネットラジオです。
後ろも一つディスプレイのついているRaspberry Pi 3Bがあります。
ちなみに記事はこちらです
認識が正確といっても良いでしょう。
まとめ
ご覧の通り、上の10行前後のプログラムで、結構「高度」な機能が実現できました。これを実現するために、Raspberry Piに特別なソフトウェア(TensorFlowやNumPy, OpenCVなど)のインストールも不要ですし、インタネットに接続しているのであれば、結果が瞬時に返ってきます。
大量な処理や、機械学習・深層学習などのプロセス自体も不要でその上、早いレスポンスと正確な認識ができます。「頭脳」の部分がRaspberry Piの外に配置するという方法も応用によってはオプションの一つですね。
今回は、Azure の Cognitive Servicesの一つしか試していないですが、他にもたくさん面白そうがAPIがあります。
- 有名人や有名なランドマークの認識
- 画像から手書きの文字や、テキストを読み取り、取り出す
- 画像の解析(画像に何が写っているか)
機会があれば、それらも実験して紹介していきたいと思います。
では、また!
弊社のページにも出しました!
興味のある方はぜひ、まず話だけでも!
連絡を待っています!#アルバイト募集 #インターン #インターンシップ https://t.co/yReHhrRfcB— 深層学習・Python・機械学習、Web、IoT (@kokensha_tech) 2019年2月3日